

In short
- The five types of borderline AI disagreed on 67% of the 1,000 real-world claims.
- One agreement was reached on only 328 claims.
- At 0.639 Krippendorff’s alpha, the sample falls below 0.8 reliability.
Ask the top five AI systems in the world if that statement is true, and two-thirds of the time, at least one will give you a different answer. It is the discovery of a a new lesson published this month by researcher Kosta Jordanov at Lenz Research.
The survey provided GPT-5.4, Claude Opus 4.7, Gemini 3 Pro, Gemini 3 Pro with Search, and Sonar Pro with over 1,000 real-time reviews from real users. The sample had to choose one of four labels: true, mostly true, misleading, or false.
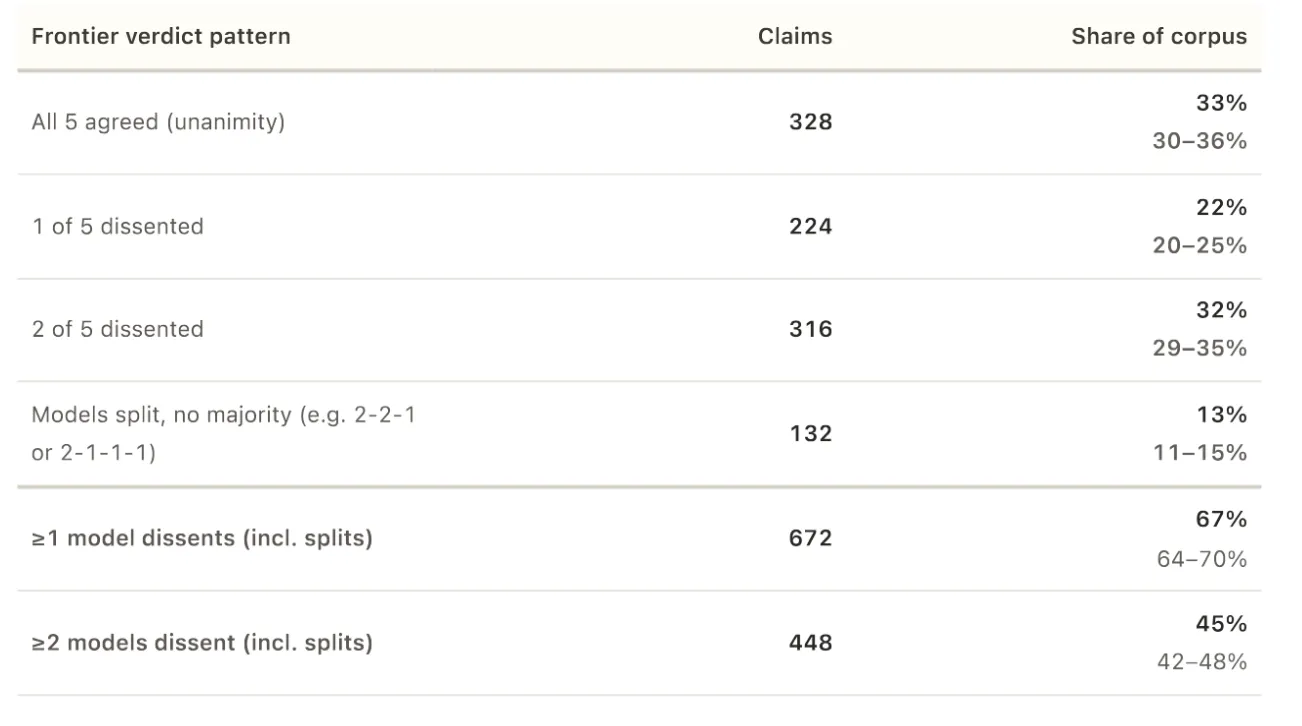
For 672 out of 1,000 statements, at least one color broke from the majority. In 34% of the cases, the disagreement was significant: one model called the statement true while the other called it false.
“This is not the content of public response keys – it’s what people use that are sent to be verified on the review platform,” the study reads. “Only one bucket of judgment can be correct in what it says, so any disagreement between the group means that the judgment of one model does not agree with the 4-bucket.”
Previous studies on AI visualization They have shown that chatbots create reality. That’s one problem. This is different. Models don’t make things, they can’t agree on the exact meaning of those things.
The study used a setup that makes it difficult for AI companies to report. Instead of extracting claims from standard tests — the kind that often go into training data — the researchers used claims that real people submitted to Lenz’s observation platform. “Many of these claims do not appear in any of the gold standard training courses – there is no official response to the comparisons against them, no benchmarking board,” the paper said.
The correlation coefficient, called Krippendorff’s alpha, reached 0.639 on the scale where 1.0 means perfect agreement and 0 means random chance. The study says this shows a “consistent but modest association.” “The judgments of the samples are prepared not randomly, but they are not consistent enough for the group to act as a single judge that can be changed,” the researchers say. Researchers generally consider anything below 0.8 to be weak.
When all five samples agreed – which happened in only 328 cases out of 1,000 – they never agreed that something was misleading or true. Only four claims received a “misleading” verdict. Zero received “mostly true”.
The researchers presented examples where AI models showed significant differences, including “The World Bank operating in Nigeria is worth more than $16.4 billion as of 2025.” ChatGPT 5.4 called it “mostly true” while Gemini 3 Pro called it “false” and its sister model Gemini 3 Pro + Search called it “misleading.”
In another example, the sample was given with the statement: “Donald Trump said that the attack on Iran was stopped at the request of the Gulf Allies.” GPT-5.4 said it was false, Claude Opus 4.7 called it true, Gemini 3 Pro said it was false, and Gemini 3 Pro + Search said it was true.
“The group changes on the definite sentences; the middle of the rubric is where it breaks down,” the researchers found. Consistency occurred in extremes: either the statement was true or it was false.
This is important because the population is increasing turning to AI systems for virtual reality. If you fake a news report in ChatGPT, Claude, or Gemini, you can get three different answers. Which do you believe in?
AI companies love to tell you that their models are working. They publish statistics that show steady improvement. But Lenz’s research tested these models on complex, ambiguous claims that real people disagreed with—and found that the models contradicted each other.
The paper is careful to point this out. “Many borderline models are not true. The majority judgment is sometimes wrong; the counterman’s model is sometimes right. We use the majority as a point of reference for disagreement, not as a representation of correctness.”
There is a deep problem buried in the numbers. When models disagree, one of them must be wrong – the study calls the decision of the model “inconsistent under this 4-bucket rubric.” There is no criminal procedure, no court of appeal. Recent reports on the reliability of AI has raised the same alarms.
Of the 328 statements where all five variables agreed, zero received an acceptable “true” rating. The bucket of nuance was completely emptied. If AI models only get overwhelming consensus, can they be trusted as evaluators at all?
Daily Debrief A letter
Start each day with top stories right here, including originals, podcasts, videos and more.



