

In short
- DeepReinforce released Ornith-1.0 on June 25 under the MIT license, designed for AI code assistants working in virtual environments and storage environments.
- The 9B model scored 69.4 on SWE-bench Verifiability, beating Google’s Gemma 4-31B (52.0).
- Ornith’s model card warns that models may work less well for non-curved tasks – they are linked to radio production pipelines, not public AI conversations.
DeepReinforce, a well-known AI research lab CUDA-L1 and IterX code-agent optimization loop, release Ornith-1.0 at the end of last week – a family of open models available on Hugging Face in four sizes depending on the number of units: 9 billion, 31 billion, 35 billion professional mix, and 397 billion mixed-professional flagship, all under the MIT license without regional restrictions.
Parameters are basically the number of dials and settings that a model can handle in its course. The more parameters, the better the model. A 9-billion-parameter model is considered small enough to run on a decent smartphone, but it can’t do heavy work reliably. The 397 billion model is very capable, but requires heavy computing, which is not available on consumer hardware.
Lab he explains is “a self-contained family of open-source models specifically for writing services.” The word-agent-does a lot of work.
Aloha! 🌺 Meet Ornith-1.0, a family of popular open source LLMs for coding.
Ornith-1.0 targets a full range of sizes including 9B Dense, 31B Dense, 35B MoE, and 397B MoE. It achieves the highest performance among open source simulation models on… pic.twitter.com/7g1rmacLps
– Ornith (@ornith_) June 25, 2026
Most AI that people interact with is conversational: you type, it responds, the exchange ends. Agent AI it’s different—it finds a task and takes action to complete it without a human guiding each step. In coding terms, this means an AI that reads files, runs tests, detects failures, corrects the code, and loops until it’s done.
So Agent AI means no one has to be at the keyboard most of the time. That’s the whole point. This is how the most relevant advances in business are happening in 2026—models that can run unsupervised and 20-step dev workflows are more important than those that write pure work when asked.
However, the vast majority of languages are still created by human imagination.
How the Ornith’s brain works
Most AI agents are combined with human-made harni—standard rules for how the agent does its job: when to call a tool, how to make a mistake, how to break down a multi-step problem. Ornith instead “sees the scaffold as a learning object that fits the process.”
Translation: instead of copying someone else’s playbook, it creates its own.
During reinforcement learning, each training session takes place in two phases. The first example reads the function and provides the best way to approach it. It then uses that method to generate a solution.
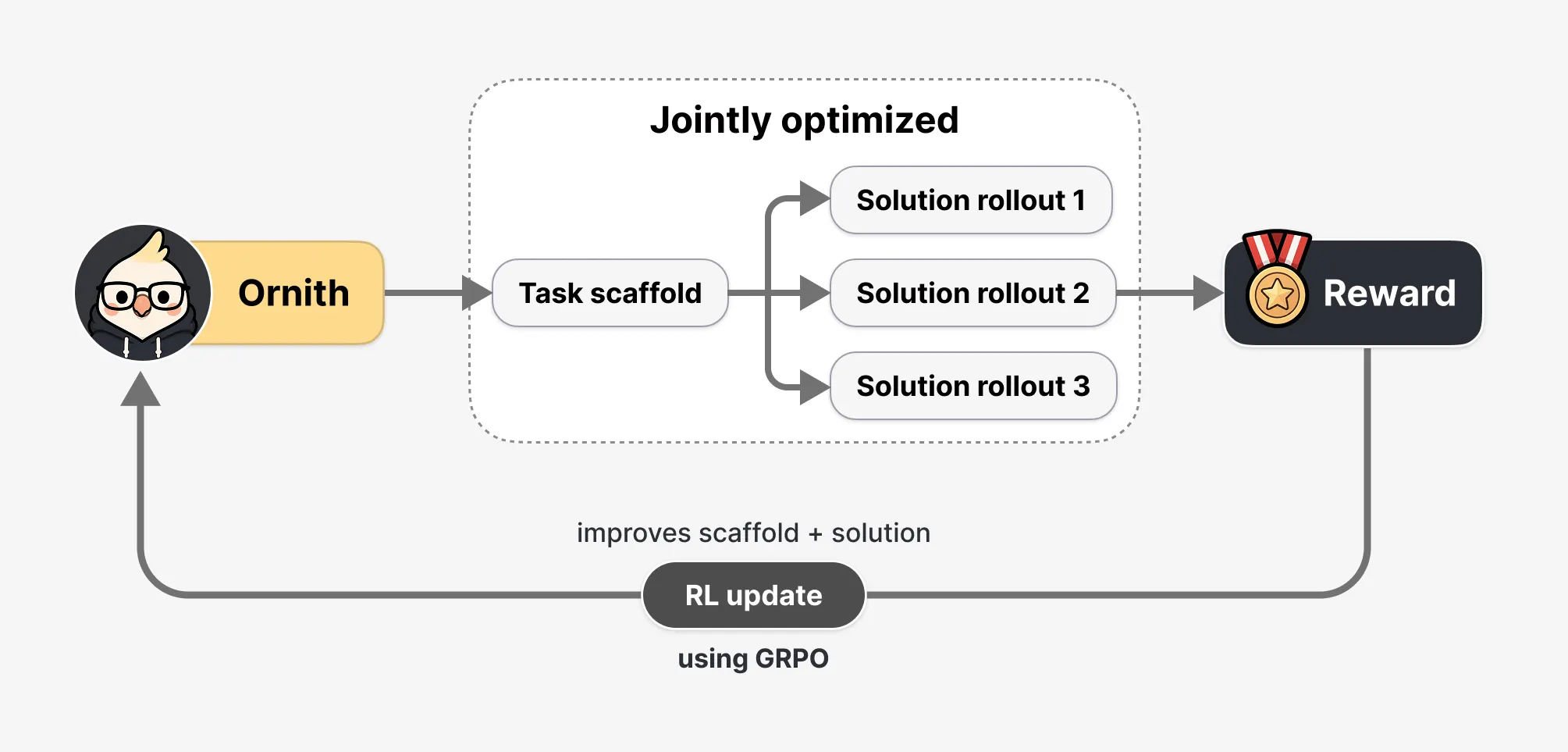
Rewards from results flow back to both parts—so the model is designed to write better methods, not better code. Do this thousands and millions of times, and real strategies emerge without anyone creating them.
DeepReinforce also takes rewards seriously. If the model can write its own training scaffold, it can write a scaffold that plays the role of verifier – touching a file to make it look like it’s done a job without actually doing the job. Three defenses block this: the environment and the test are immutable and cannot reach the model, the monitoring system looks for any attempt to enter prohibited methods or change the verification documents, and the cold judge sits on top of the automatic verification as a veto.
Numbers
The 397 billion views put 82.4 on the SWE-bench Verified-test where the AI is given a real bug from the open source GitHub and has to fix it without seeing the test, which they found as the number of problems that they solve successfully.
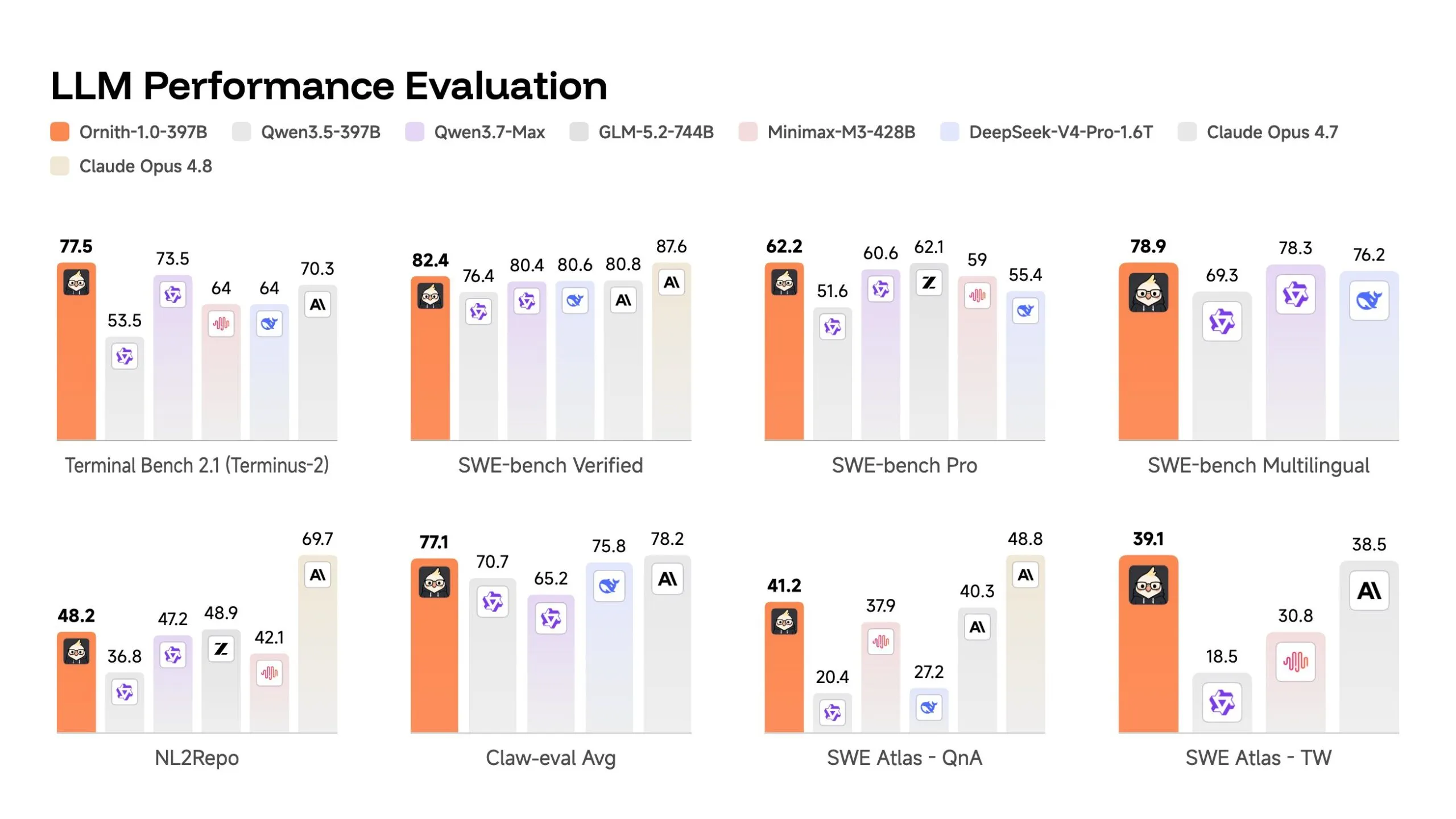
This beats Claude Opus 4.7’s 80.8 and DeepSeek-V4-Pro’s 80.6 in the same test. On Terminal Bench 2.1-89 tasks run through the repository from changing async code to solving security threats, which reaches the final result – it scores 77.5 against Claude Opus 4.7’s 70.3.
Given that Benchmark contamination issues for SWE has been publicly raised-OpenAI argued earlier this year that the models raised a lot by memorizing the answers seen during training-Ornith also shows statistics on SWE-bench Pro, a more complex version of using different codebases, without crossing the same one. A sample of 397 billion reaches 62.2 there. Low definition, but still competitive in this segment, and better than Deepseek V4 Pro.
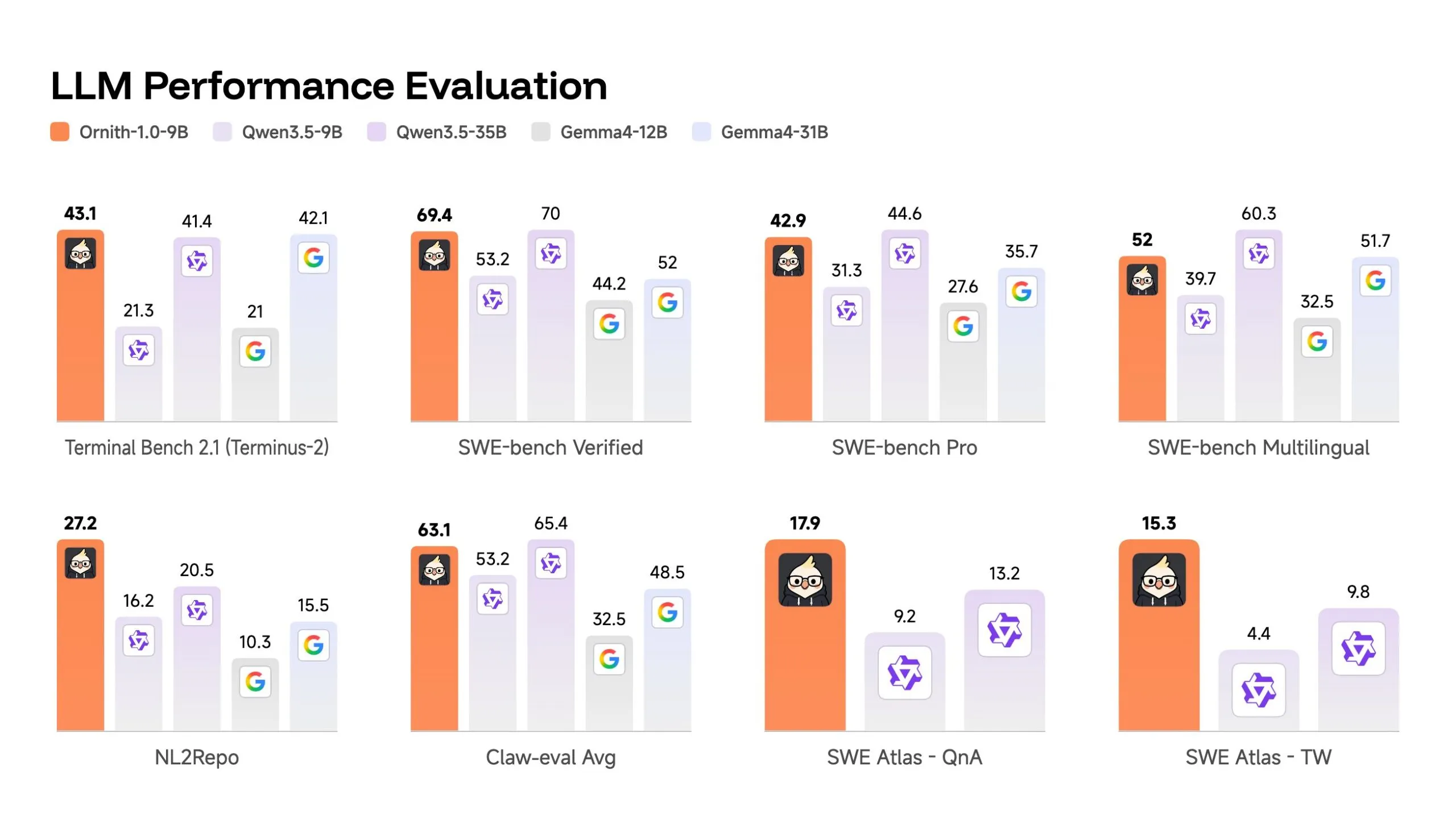
The 9 billion parameter model can be a very interesting place. It ranks 69.4 on SWE-benchmark-higher than Gemma 4-31B’s 52 and competitive with Qwen 3.5-35B’s 70, although it was 3-4 times smaller.
Whose, whose
Ornith-1.0 is no ordinary AI. The model’s documentation states that it may perform less well for applications outside of codecs. If you want AI to summarize a document, help you write your doctor’s opinion, or write an email, Ornith-1.0 is the wrong choice.
It is designed to have a minimal problem: programming pipelines where an AI assistant takes a job description, works within a database or a final stage, and completes multi-step tasks without intervention. This is a tool designed for people who are already running infrastructure – not for people who are trying to decide if AI is worth using.
The title “Beats Claude” is real but it needs a story. Like Decrypt also saidEvery lab is running performance tests on coding evals, because that’s where the performance differences lie.
Ornith-1.0-397B outperforms Claude Opus 4.7 on all different benchmarks, but Anthropic’s current record, Claude Opus 4.8, is much higher. The available comparisons are within the open group, on the corresponding statistics, on the special services of the agent.
For Developers who only build pipelines, tooling, or similar standard work, the small and medium models running on peripherals may be useful, but the average Joe may look elsewhere.
Daily Debrief A letter
Start each day with top stories right here, including originals, podcasts, videos and more.



