

In short
- ARFBench is the first AI benchmark built from real production scenarios.
- GPT-5 leads all existing AI models at 62.7% accuracy but falls short of the control experts at 72.7%.
- An expert-level explanation—combining AI and human judgment—hit an accuracy of 87.2%, setting the ceiling for what AI-human collaboration teams can achieve.
The AI industry continues to be independent trusted site for support engineers-AI that investigates artificial intelligence on behalf of humans. Datadog ran a real benchmark for real shutdowns, and the best AI models can’t beat the engineers who need to change.
The benchmark is ARFBench (Anomaly Reasoning Framework Benchmark), a joint project from Datadog and Carnegie Mellon. Created from 63 real-life scenarios, taken from Slack engineer threads during emergencies—750 multiple-choice questions about 142 analytical metrics and 5.38 million data points, each question is verified by hand. There is no production data. There are no book events.
“Billions of dollars are lost each year due to system failures,” the researchers wrote. The benchmark tests whether AI can really help change this.
“Despite the large role of question-driven analysis in answering empirical questions, it is unclear whether current models can reliably answer the questions that practitioners ask in practice,” the paper said.
Questions come in three categories. Step 1: Is there something wrong with this chart? Part II: When did it start, how hard is it, what kind?
The third step – the most difficult – requires careful consideration: Is this chart causing a problem in the other chart? That’s where AI falls down. GPT-5 achieved only 47.5% F1 for the Tier 3 questions, a metric that penalizes game answer samples by selecting the most popular class.
“Despite the large role of query-driven analysis in answering these questions, it is unclear whether current models can reliably answer the kinds of questions that engineers ask in practice,” the researchers wrote.
How each type stacked up
GPT-5 topped all available models at 62.7% correct-on-test while random guessing achieved 24.5%. Gemini 3 Pro scored 58.1%. Claude Opus 4.6: 54.8%. Claude Sonnet 4.5: 47.2%.
Domain experts achieved an accuracy of 72.7%. Non-domain experts—time researchers at Datadog with no visible experience—hit 69.7%.
There is no type of AI that surpasses human origins.
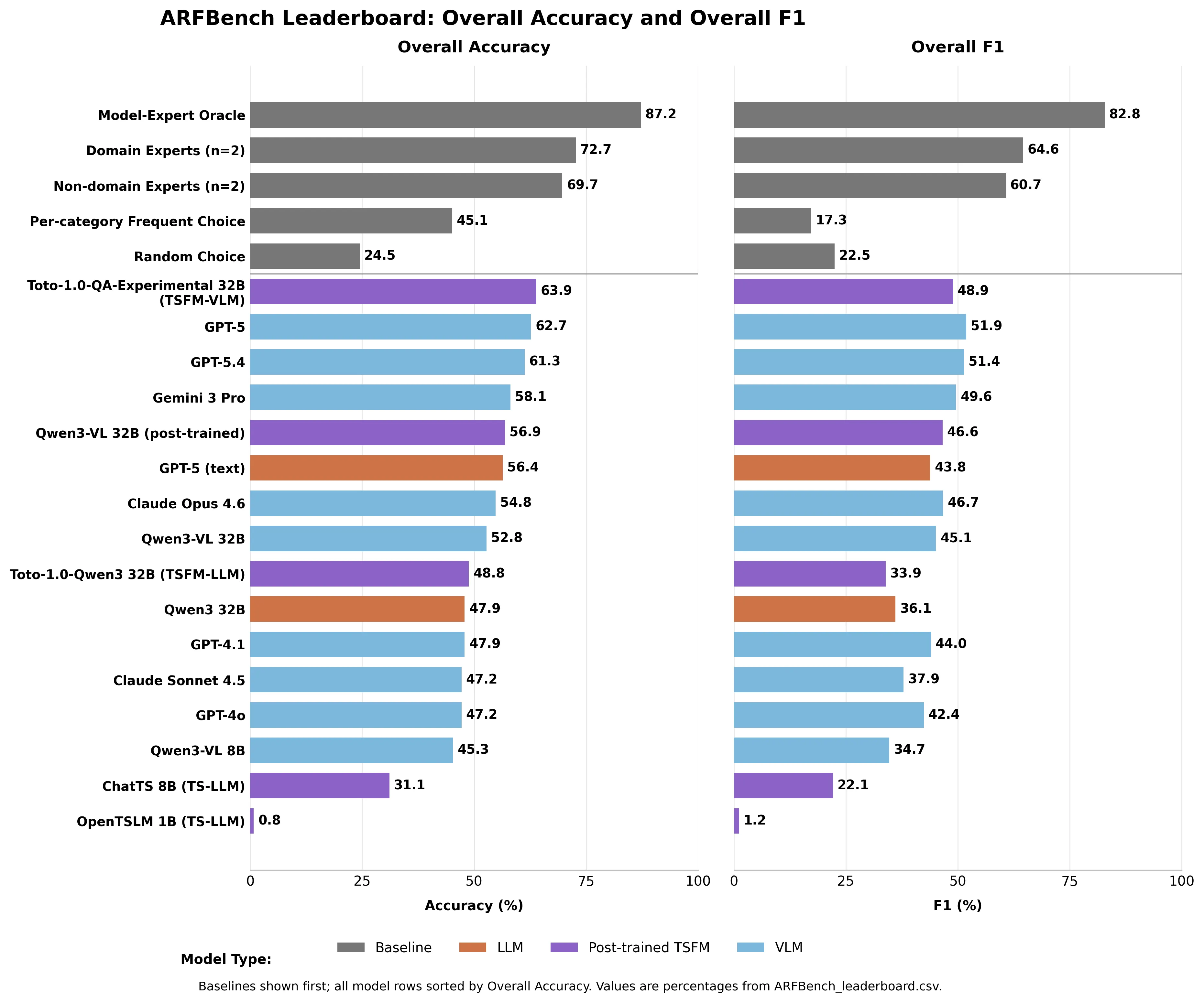
The model that topped the board was Datadog’s hybrid: Toto – their in-house time prediction model – paired with the Qwen3-VL 32B. Toto-1.0-QA-Experimental achieved 63.9% accuracy, outperforming the previous GPT-5 using its parameters. On a more familiar note, it outscored every other race by at least 8.8 percent in F1.
The goal-based system, trained on visual information, outperforms the all-purpose system at the boundary in this task and is the expected result. That’s the point.
The most important achievement is not the most successful.
The researchers write: “We observe different errors between the leading experts and the human experts, which suggests that their strengths are related.” Examples include displays, missing metadata, and losing domains. People misread the correct stamps and sometimes fail to follow difficult instructions. The mistakes cannot be compared.
An example of the “Model-Expert Oracle” theory – a perfect judge who always chooses the correct answer between AI and human – and you get 87.2% accuracy and 82.8% F1. Way above or alone.
It is not a drug. It’s a written target– built from real experiences, not archived – that determine how well human-AI collaboration can work. The guide is available at Hugging Face. GPT-5 stands at 62.7%. The ceiling is 87.2%.
Daily Debrief A letter
Start each day with top stories right here, including originals, podcasts, videos and more.



