

In short
- Xiaomi and its TileRT partner have broken 1,000 tokens per second on a 1-trillion-parameter model, the first time at that level, using an 8-GPU commodity node—not conventional chips.
- The speed comes from FP4 quantization on the professional part of the model and DFlash virtual decoding, which generates the entire block of signals in one pass instead of one at a time.
- A limited number of API tests open June 9 through June 23, at a cost of 3 × MiMo measures at about 10 × generation speed.
Most people know Xiaomi as a Chinese smartphone brand. Which makes electric scooters cheap and clean. Not exactly a company you’d expect to break a big AI record on Monday morning.
And yet. Xiaomi has just launched MiMo-V2.5-Pro-UltraSpeedits trillion-parameter token delivery system hits more than 1,000 tokens per second – peaking at around 1,200 in demos.
Parameters are internal numerical measurements that define how a model behaves—the more you have, the more difficult it can figure out. Symbols are the parts of words that the type reads and writes, about three-thirds of each word.
Xiaomi did it on one of the 8-GPU models. Standard equipment, no custom chips. This changes the calculation of who can use this type of speed in production.
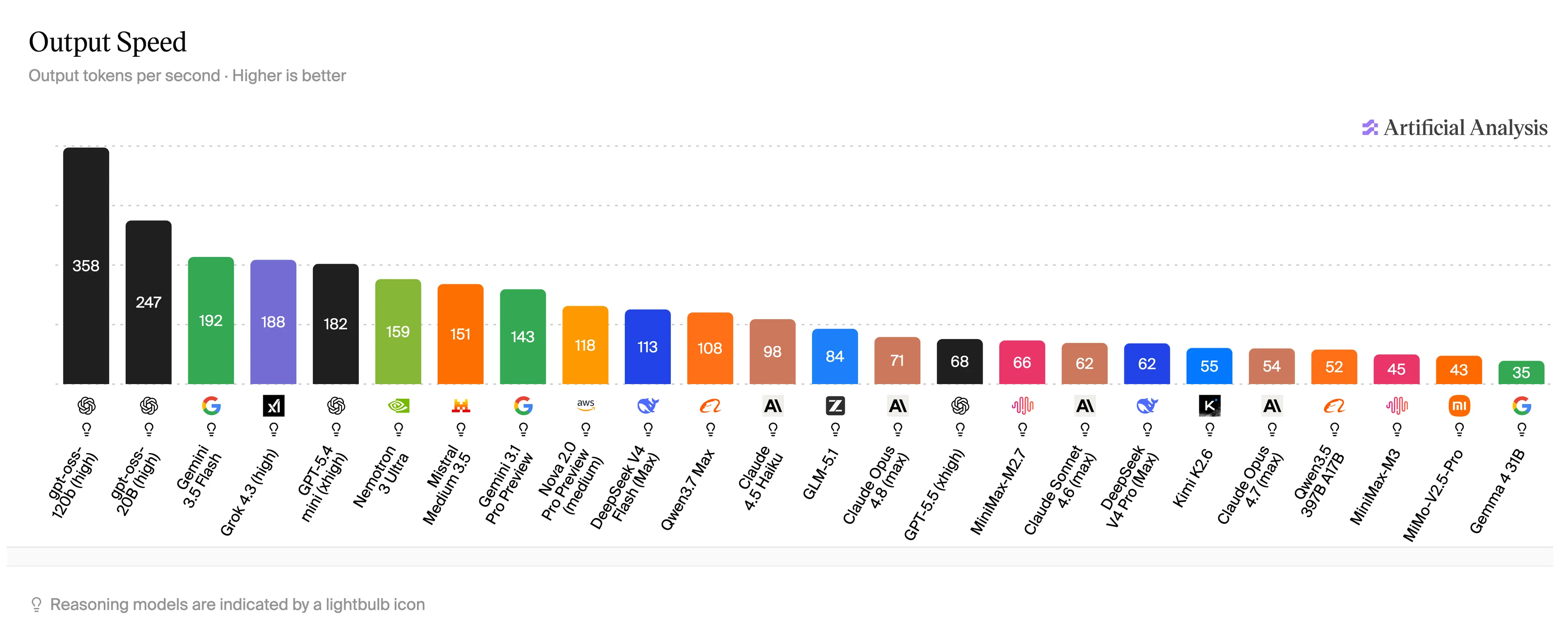
To put this number in human terms: pa Production AnalysisGPT-5.5-which many users of ChatGPT are talking about-is at 68. Claude Opus 4.6 comes close to 71 and the lowest example, Haiku, about 98 symbols per minute. Gemini Flash hits 192 tokens per second. MiMo-V2.5-Pro-UltraSpeed / is is is is is is is is is is is is is is the same as Opus in coding benchmarks.
Cerebras and Groq built entire businesses around this problem. Cerebras designed the chip to be the size of a dinner plate, packing 44GB of on-chip memory to eliminate the bandwidth bottleneck that limits GPU performance. It hit 969 tokens per second on Meta’s Llama 3.1 405B—impressive, but it’s a 405-billion-parameter model, less than half the size of the MiMo-V2.5-Pro. Groq culture Language Processing Unit Buildings average 300-750 tokens per second depending on the model.
Not even the hardware you can rent from AWS tonight.
Xiaomi has done it on expensive GPUs through the software itself – including color intelligence and a purpose-built engine called TileRT.
What’s going on under the hood
Two ways carry speed. The first method is called FP4 Quantization: instead of running the model with a high precision of 8-bit or 16-bit, Xiaomi reduces the professional components – which make up more than 1 trillion components – to 4-bit. Memory footprint goes down, bandwidth goes down, speed goes up. The fish are usually slightly damaged. Xiaomi’s configuration and operation: only professional components are compressed, everything else is correct. With this method, the quality loss is defined as near-zero.
The second is DFlash speculative decoding. Standard hypothesis testing consists of a small sample that compares several outcomes, then a large sample that predicts them equally. DFlash skips sequential writing entirely – it fills in a lot of hidden space in one go. In writing tasks, the main example receives an average of 6.3 out of 8 requested tokens per round of authentication. That’s six signs confirmed in one step instead of one.
TileRT connects together. It keeps all the integration pipelines internal to the GPU—no initializers to launch, no slots to kill.
Xiaomi calls this method “the highest quality token,” and the statement is correct: There is no single method that reaches 1,000 tokens per second, but the cooperation between all methods does.
MiMo V2.5 Pro is an example of a limit. We covered the launch of V2.5 Pro in April—it’s comparable to Claude Opus on most benchmarks and runs around $0.43 / $0.87 in output per million tokens. Opus costs $5 input/$25 output per million tokens.
UltraSpeed supports the same version of MiMo V2.5 Pro, not the unlocked version.
A quick enough control changes the way you use the model. You can run multiple thinking processes in parallel instead of waiting for a single answer. Fraud detection, transaction intelligence generation, real-time loops—all of these have latency issues that 60 tokens per second cannot meet. At 1,000 marks per second, they can.
Xiaomi is making the prices three times the amount of MiMo-V2.5-Pro API testing will take place from June 9-23, depending on the application, and prioritization of companies and developers. The FP4-DFlash forum is already open on Hugging Face community testing.
Daily Debrief A letter
Start each day with top stories right here, including originals, podcasts, videos and more.



