

In short
- Opus 4.8 successfully passed the math and produced the cleanest game we’ve ever tested.
- That single outage destroyed our entire Pro token pool, making the model unworkable for large projects without a Max plan or significant API investment.
- Creative writing has not changed against 4.7.
Six weeks after Opus 4.7, Anthropic was shipped Close Task 4.8. Benchmarks have increased, security has increased, and the price has not dropped from $5 per million tokens and $25 per million issued.
So we ran the same tests that we test for all areas—writing, writing, math, logic, descriptive reasoning, and long-term memory—and compared them head-to-head with their predecessors and the Chinese version that continues.
Short version: 4.8 is good for things that Claude used to be good at (things like math, writing, mechanical things), and slightly worse for things that he used to be bad for (things like ideas, creative writing, etc.). It also has an appetite that prevents self-destruction.
Here’s the breakdown.
Creative Writing
The information is the same as we used before MiMo and Qwen: a time travel story rooted in the author’s culture, set in a specific historical place, built around a paradox where time cannot be changed. Opus 4.8 went to Venezuela, probably because it profiles users and knows I’m Venezuelan. AI established what happened in the Orinoco River in the year 1000, the forgiveness of Maracaibo named José Lanz (my name) sent again 11 years to kill music.
His words are clear. The river is “green in a way that 2150 forgot it could be green,” palafitos hover over the coffee-colored water, and macaws tear through the air “with screaming red-and-gold stripes.” The surprise also arrives cleanly: the protagonist is sent to destroy the creation of a song that affected the social change that started his dystopian society thousands of years in the future-however, when he arrives with the intention of criticizing the composer, he realizes that there is no composer. Whoever made the song did it in his honor, the song is about him, and he can’t disrespect himself, it’s closed.
The piece ends with “It worked perfectly. As a built object, it is pure and artistic.
But cleaning is not the same as living. The writing explains without being watery what it is MiMo v2.5 production—low speed, few surprises, unpleasant and difficult to understand what happened from the beginning. Beside Opus 4.7, it’s hard to call it a change; if anything, it’s a hair back. Deeper thinking and different shots can push you to the front of the pack – but just one pass away, this is the next best move.
You can read the whole story in Our Github.
Coding
Our coding tests are a custom way to create a single game. Opus 4.8 created a typing-zombie-gameTyping Dead– That was great. The best splash screen, the best zombie designs, the best mechanics we’ve found in this test from any Anthropic brand.
The model caught a few of its mid-range bugs and fixed them before we reported. Its real power, however, was evident in different shots: each trace is polished and improves the architecture instead of breaking it, which is a failsafe method that confuses many models as the codebase grows. This is what Anthropic is all about.
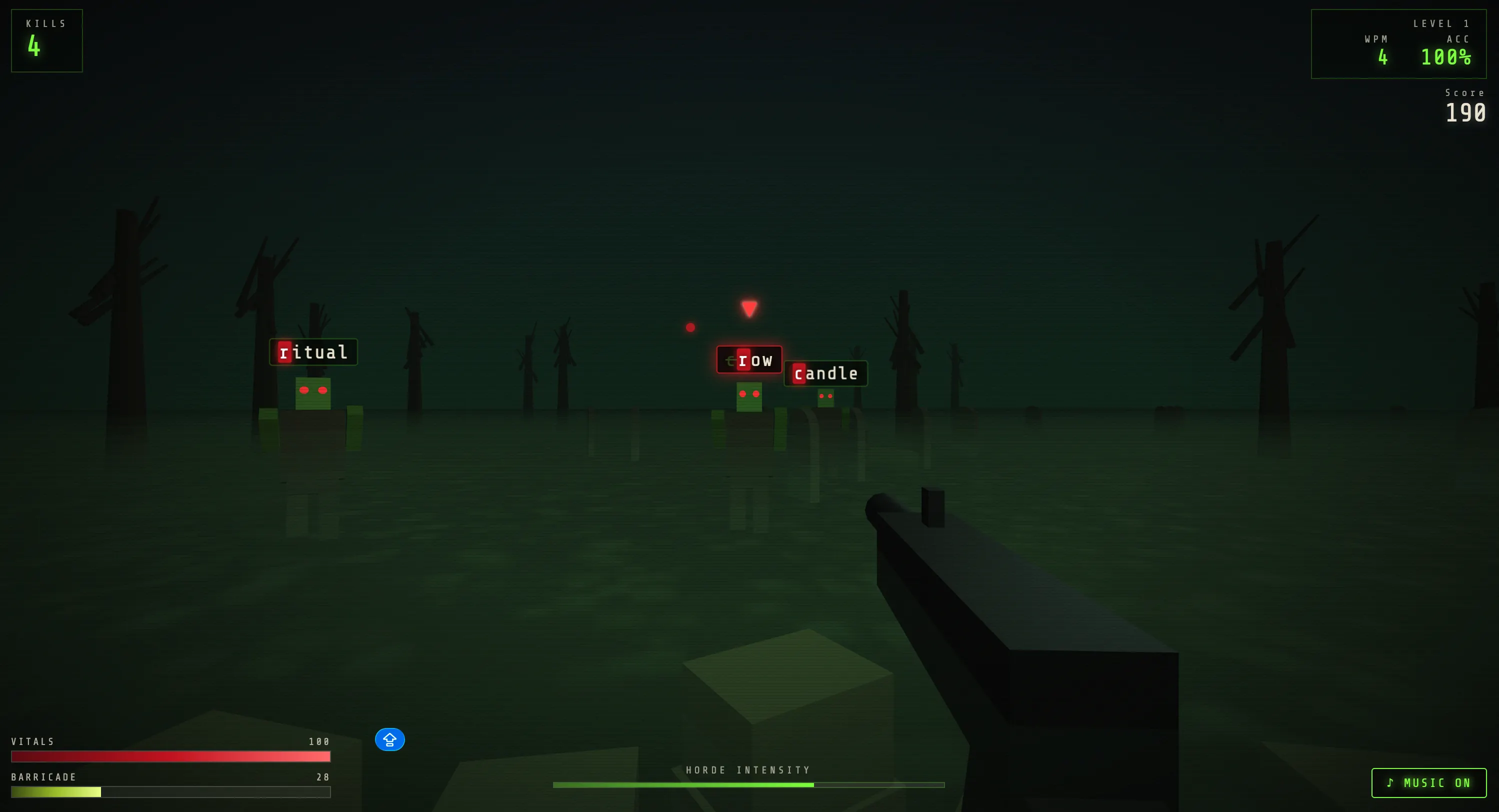
After one iteration, our game became much better, with our fighters moving around, changing views, improving sound and visuals, and more.
You can pay the second game on our Itch.io profile.
This is when it bit us. One rush wiped out our entire share of tokens – at once. For anyone on the Pro plan, this makes Opus 4.8 unsuitable for any real-world project. You’ll burn your portion before lunch and spend the afternoon watching the bar while waiting for a refill.
Mathematics
The math test is our FrontierMath section: create a degree-19 polynomial whose curve X = {p(x) = p(y)} has three invariant components-but not all linear-makes it odd, monic, real, linearly equal to -19, then integrate p(19). It’s a problem that sends many models into a loop or a shortcut that is silently wrong.
Opus 4.8 performed well. It recognized the Dickson/Chebyshev construction, identified a dihedral monodromy that gives exactly 10 elements – one diagonal line plus nine conics – and calculated p(19) = 1,876,572,071,974,094,803,391,179 using proper iteration. No cold, no smoke.

This is important because Opus 4.7 is still not there despite many attempts. This is a real, visible-sounding benefit throughout the battery.
You can read the full answer Our Github.
Logic and Common Sense
Haste is an old trap: Is it legal for a man to marry his widow’s sister under Falkland Islands law? The catch is language, not legal – if a man has a widow, she’s dead, which makes the question null and void as written.
MiMo also answered the question in silence and answered the proposed version without contradicting the arguments. Opus 4.8 didn’t take that shortcut. It explained the trap very clearly – “if a man has a widow, he is dead” – he answered the specific question first, then gave a proper analysis of the intended one, referring to the Marriage of the Sister of a Deceased Wife Act 1907 and the Marriage Act of the Falkland Islands.
Here’s how to deal with it: point out the objections, then help, don’t silently assume what the user means. It’s the same standard as the Qwen 3.7 Max set, with a clean rating of 4.8 — good thinking, good transparency.
The complete answer is available here.
Non-Mathematical Discussion
Here is the one that lost. The puzzle is a whodunit—a winter school trip, three kidnappings, an innocent child about to be punished, and a timeline you must follow to name the stalker. The correct answer is Leo.
Opus 4.8 made a convincing story, convinced that Leo was innocent – a half-hour walk to the shower, a jacket that was wet in some places and dry in others, “strange behavior” read as frustration rather than guilt – and put the crime on Eric, “who was found unknown all night.” Imagination is beautiful inside. It is also wrong.
And this is what researchers have been warning about LLMs. He believes strongly even when he makes a mistake. It usually takes an expert (in this case we know the correct answer in advance) to see one of those things. A person who uses AI in research, or a person who blindly trusts AI, may face negative consequences depending on the task they are asking the AI to perform.
That’s what makes failure fun. The model was too clever to construct a watertight alibi for the real culprit and put a stand-in in his place. Opus 4.7 found the correct answer. Sometimes more horsepower just buys you a more tempting way to make a mistake. It only takes one small deviation to start making many wrong assumptions.
You can see the full answer at Our Github.
A needle in a haystack
We ran two hay cannons. The 300K symbol range never went down – the sample fell below its size and could not be processed at all. So much for marketing millions of dollars once you deliver the world’s richest product. This seems to be for the API only.
The 85K version was optimized, and the version found all the needles we buried inside The Decrypt’s Dictionary: the planted line (“The Decrypt dudes read Emerge News”) and the truth (“My mother’s name is Carmen Diaz Golindano”). It is best known as a non-literal translation of Ambrose Bierce’s 1906 text.
Then it refused to answer. Believing it was being quickly injected or deemed “outlandish,” the brand refused to report its findings. The needle was found—and Anthropic behavior studies wouldn’t allow it to say so. Security beyond the work that the model has already completed is its unusual failure.
Judgment
The pattern across all six tests is consistent: Opus 4.8 makes Claude better for what he already had, and probably worse for what was already bad. This tells you who Anthropic is targeting – coders, especially coders with money. Creative writing is well ahead of ChatGPT, sure, but the difference between 4.8, 4.7, and even 4.5 in prose is hard to see.
Developers seem like an anthropic vision of the future, and that’s certainly true of the big AI companies right now.
Then there’s the problem of branding, which is a walking meme in the AI community for a reason. Anthropic deliberately made the new Opus tokenizer inefficient, so it consumes a lot of tokens to reset it quickly. Useful for builders and abuse with concrete. It leaves you with three options.
First: wait hours for your code section to restart. Second: moving to Claude Max – which is, conveniently, where Anthropic seems to be leading everyone. Third: switch to a cheaper, comparable provider—OpenAI, with longer quotas, or Chinese brands that provide comparable results at less than 25% of the cost.
It’s much harder for an average coder who can’t eat $100-to-$200 a month to move to a competitor than for a single developer to pay 10x more for a brand that may not be 10x more capable than their founders. This is the bet Anthropic is making against its foundation.
And yet the process seems to be going well. Anthropic form ready to go public at a cost of close to $1 trillion – so who are we to judge.
Daily Debrief A letter
Start each day with top stories right here, including originals, podcasts, videos and more.



